-
Peter J. Keleher authoredPeter J. Keleher authored

Code owners
Assign users and groups as approvers for specific file changes. Learn more.
pbft.md 3.34 KiB
Practical Byzantine Fault Tolerence (Castro and Liskov)
Assumptions
- operations are deterministic
- replicas start in the same state
- i.e., correct replicas will return identical results.
Differences from fail-stop consensus
- 3f+1 replicas instead of 2f+1 (non-byzantine consensus):
- must be possible to make progress w/ only n - f replicas (because f might be faulty and respond)
- however, the f not responding might be correct but slow (asynchrony), so there might be f bad responses in the n - f responses
- implies (n - f - f) > f, or n >= 3f + 1 in order to guarantee majority
- 3 phases instead of two
- cryptographic signatures
Properties
- safety, liveness (n >= 3f+1)
- can't prove both in async environment
- safety guaranteed through protocol
- so liveness must be "guaranteed" by limits on asynchrony (e.g., reasonable assumption on msg delays)
- performance
- one round trip for reads
- 2 round trips for read/write
Independent failure modes
- different security provisions (root passwd etc)
- different implementations !!
Definitions
- a view is a configuration of the system w/ one replica the primary and the others backups.
-
byzantine faults: adversary(s) can
- coordinate faulty nodes
- delay communication of non-faulty nodes (but not indefinitely)
- equivocation
- say "yes" to Larry, "no" to "Moe"
- lie about received messages
cool things
- much more robust/secure than paxos
- one extra round, at most
- little other cost
- authenticators
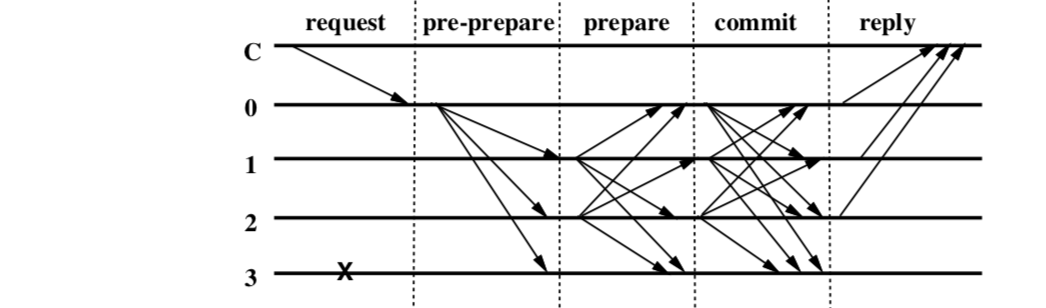
Rough outline
- client sends request to invoke an operation to the primary
- Primary multicasts request to backups
- Replicas execute the request and send replies to the client
- Client waits for f+1replies from different reqplicas w/ same result
- guarantees:
- safety and liveness (assuming only \left\lfloor \frac{n-1}{3}} \right\rfloorfaulty, delay(t) does not grow faster than t indefinitely
- safety and liveness (assuming only
Phases
-
pre-prepare and prepare phases order request even if primary faulty
- replica tells all others what the primary told it
-
prepare and commit phases ensure commits are totally ordered across views
-
a replica is prepared when:
- has received a proper pre-prepare from primary, signature, current view
- 2f "prepares" from other replicas that match it
- Such a replica then:
- multicasts "commit" to other replicas
-
a replica is committed-local iff:
- committed, and
- has accepted 2f+1 commit msgs (possibly including it's own)
-
system is committed iff prepared true for f+1 replicas
- committed true iff committed-local true for some non-faulty replica
Optimizations
- Most replies to clients just hashes of authenticated proof.
- a single replica sends entire proof
- Replicas execute once prepared and reply to clients before commit
- client waits for 2f+1 matching replies
- message delays down from 5 to 4
- Read-only ops send directly to all replicas
- rep waits until prior ops committed
- client waits for 2f+1 replies
-
authenticators. Rather than public-key sig among replicas:
- assume symmetric key between each replica pair
- rep r signs by encrypting msg digest w/ each other rep
- vector of such sigs is the authenticator
Questions
- how else can we do byzantine fault tolerance?