-
Peter J. Keleher authoredPeter J. Keleher authored

Spanner
Construction:
- a single universe
- universe has many zones, each either a server farm or a part of one. The unit of physical replication.
- each zone has 100 .. several thousand spanservers
- a spanserver consists of multiple replicas
Spanserver:

-
implements between 100 and 1000 tablets
-
a tablet is a bag of mappings:
(key:string, timestamp:int64) --> string
-
runs a Paxos (long-lived leaders) instance on top of each tablet.
Paxos group
- leader replica implements lock table
- two-phase locking
- leader also implements a transaction manager
Transaction implementation
- If only a single Paxos instance (single tablet) involved, transaction manager skipped.
- Otherwise, two-phase commit across the paxos leaders.
Directories (buckets)
- tags in a tablet that have common prefixes
- smallest unit of placement by apps
Data Model
- schematized semi-relational tables
- query language
- general-purpose read/write transactions
Motivated by:
- popularity of megastore, even though it's slow
- popularity of Dremel (data analysis tool)
- complaints about bigtable: even cons across data centers, no "cross-row" transactions (Percolator built to address this)
TrueTime

Node time:
- TimeMaster machines per data center (GPS and/or atomic clocks)
- timeslave daemon per machine
- Marzullo's algorithm to reject outlying masters
- slowly increasing uncertainty between time syncs: ε between 1 and 7ms
Operations:
- read-write transactions
- read-only transactions
- snapshot reads
- transactions are
internallyre-tried (client not involved) - implicit extension of leases by successfull writes
Assigning timestamps to RW transactions
- two-phase locking
- timestamp can be any time after all locks acquired, before any locks released
- spanners assigns trans the timestamp paxos gives the trans commit write
If start of T2 is after commit of T1, then the commit timestamp of T2 must be greater than that of T1.
Commit wait: Coordinator leader ensure that clients cannot see any data committed by Ti until TT.after(s_i) is true
- expected wait is at least 2 * Ε
- wait is usually overlapped w/ Paxos execution
Thoughts:
- ian: synergy between long-lived leaders and two-phase locking.
- would love to know how active
MoveDiris, and more about it's policies.
CockroachDB: Life Without Atomic Clocks
Quotes
- "our challenge was in providing similar guarantees of external consistency without atomic clocks."
- "A system which provides an absolute ordering of causally related events, regardless of observer, provides for a particularly strong guarantee of external consistency known as “linearizability.”
- "in a non-distributed database, serializability implies linearizability"
- single clock
- if T2 starts after T1 finishes, that will be equiv serial order, and so...
- "CockroachDB’s external consistency guarantee is by default only serializability, though with some features that can help bridge the gap in practice."
"Before a node is allowed to report that a transaction has committed, it must wait 7ms. Because all clocks in the system are within 7ms of each other, waiting 7ms means that no subsequent transaction may commit at an earlier timestamp, even if the earlier transaction was committed on a node with a clock which was fast by the maximum 7ms"
Approach:
-
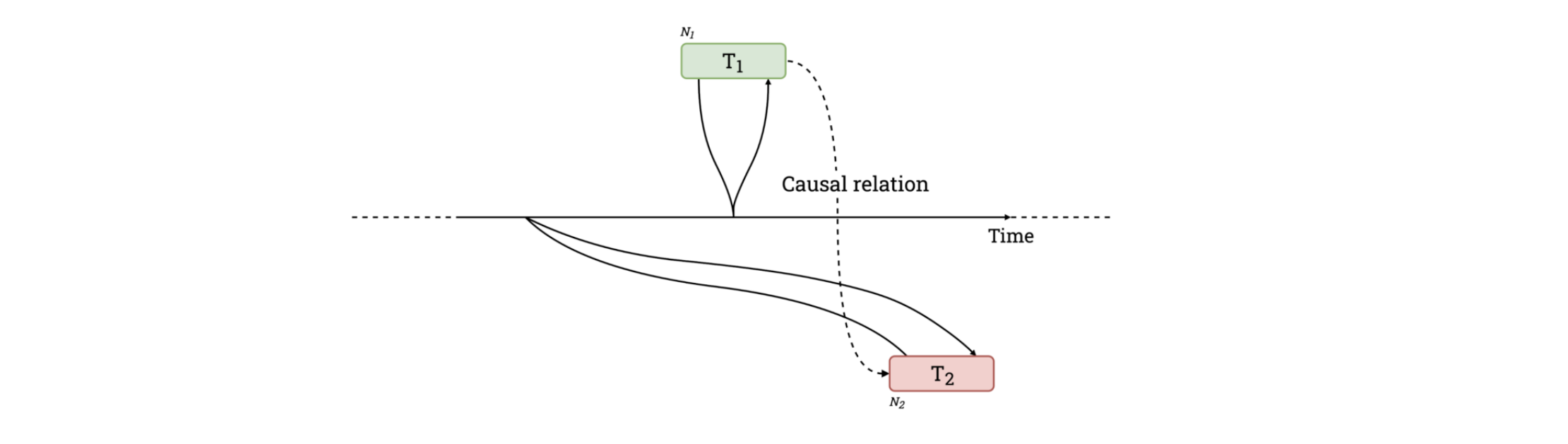
"The possibility of reordering commit timestamps for causally related transactions is likely a marginal problem in practice."
-
"What could happen is that examining the database at a historical timestamp might yield paradoxical situations where transaction A is not yet visible while transaction B is, even though transaction A is known to have preceded B, as they’re causally related. However, this can only happen if there’s no overlap between the keys read or written during the transactions."
Approach
causality token - max timestamp encountered (anywhere) in a transaction.
- used to ensure that causal chains maintained by serving as minimum commit timestamp for that transaction.
Problem:
- Ti reading data from mult nodes might fail to read already-committed data
Solution:
- choose xtion timestamp based on node wall time: [commit timestamp , commit timestamp + max uncertainty]
- define upper bound by adding maxoffset
- read quickly as long as no version seen s.t.:
- version after commit timestamp
- but before upper bound
- if so, re-start transaction w/ version's timestamp
- upper bound doesn't change.
- lower bound gets higher, just above the problematic node write (window shrinks)
- never restart based on same-key version read from same node in one transaction.
So:
- spanner always short-waits on writes for short interval (~7ms)
- cockroachdb sometimes long waits on reads (~250ms)
- causal reverse still possible (though probably not a problem in practice)
Strict serializability makes all of the guarantees of one-copy serializability that we discussed above. In addition, it guarantees that if a transaction X completed before transaction Y started (in real time) then X will be placed before Y in the serial order