# Implementing Linearizability at Large Scale and Low Latency
## RAMCloud
- basically all RAM
- "durable writes" get replicated in other RAM
- log-structured, *cleaner* etc.
- massively parallel, 5 usec end-to-end RPCs.
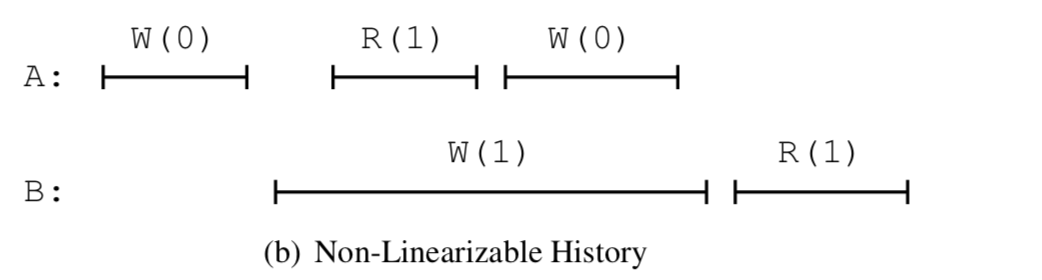
**Linearizability**:
- collection of operations is *linearizable* if each operation appears to occur **instantaneously** and exactly once at **some point in time between its invocation and its completion**.
-**must not be possible** for any client of the system, either the one initiating an operation or other clients operating concurrently, **to observe contradictory behavior**
Good:

Bad:

Retry of idempotent operation bad:

Bottom line:
-*at-least-once* bad
-*exactly-once* good
- detect and stop retry of completed op
- return same value as first execution
## Architecture
RPC's needed so that clients can be notified of completed operations.
Problems / solutions:
- RPC identification
- globally unique names
-**completion record** durability
- must be atomic wrt the actual mutation
- store completion record w/ object
- retry rendezvous
- find record, even if sent to different server
- store completion record w/ object
- for transactions, pick one datum
- garbage collection: when we know request will never be retried
- after client acks response
- after client crashes
## Client failure detection
- leases
- must renew
- essentially a heartbeat
- want to scale to **a million clients**???!
## Lifetime of an RPC
When received by server:
-`checkDuplicate()` in ResultTracker (on *server*)
- normal case returns new, proceeds
- completed previously, returns previous value
- in-progress (toss the request or nack the client)
- stale retry - error to client
-*normal case of new RPC*
- execute the RPC
- create completion record
- return to client
-*asssumes some local durable log*
## Design
`RequestTracker` (on client)
- tracks active RPCs
-`firstIncomplete` sequence number added to outgoing RPCs to servers
- server deletes records for earlier RPCs
- only 512 outstanding RPCs from single client
`LeaseTracker` (on clients and servers)
`ResultTracker` (on server)
### Lifetime of RPC
- new RPC - unique identifier using client ID w/ new seq num from RequestTracker (from server?)
- server calls `checkDuplicate`: new / completed / in_progress / stale
- server executes
1. creates RPC identifier
1. creates object identifier (completion record w/ migrate w/ object)
1. result returns
1. operation side effects and completion record **appended to a log atomically**
1.`recordCompletion` on ResultTracker, system-dependent
1. return result to client
### Lease management
- Zookeeper
- renewal overhead
- low because *stable storage not updated on renewal*
- validation overhead
- in-memory
-*cluster clock* for server's to do most lease validation
- ask lease server only when close to expiration
## Transactions with RIFL (RAMCloud implementation)
- sinfonia-ish two-phase commit:
-`prepare` (version/lock checks)
-`decision` (this phase in background, client already notified)
("the transaction is effectively committed once a durable lock record has been written for each of the objects")
- updates deferred until commit request
- reads executed normally, *versions recorded*
- writes on commit phase, possibly w/ expected version
- fail *if version-check fails, or locked by another transaction*
- fast case
-*single server* owns all objects in transaction
-*read-only*, even in distributed case only a single round
- on client crash, recovery coordinator finishes, hoping to abort unless already committed
## Issues
- worried that storing completion records will not scale well
- local operation
- either disk or (for RAMCloud) replicating elsewhere
- why optional version checking in transactions? (atomic operation primitive)

{kind=link}

{kind=link}
{kind=link}
